Deep Learning: Detecting Fraudulent Healthcare Provider using AutoEncoder

Introduction
In this article, I will share my experience that how to use the power of deep neural networks to effectively identify fraudulent healthcare providers from the health care transactions that can be identified as anomalies in a dataset. For this solution, I used autoencoder machine learning algorithm and implemented it in the H2O platform.
Let us start with the definition. An anomaly refers to a data instance that is significantly different from other instances in the dataset. Often these considered as statistical outliers or errors in the data before developing a predictive model. But sometimes an anomaly in the data may indicate some potentially harmful events that have occurred previously. In health care insurance claim data, those are fraudulent claims.
Health Care Fraud
 Healthcare provider fraud is one of the biggest problems facing Medicare. According to the government, the total Medicare spending increased exponentially due to fraud in Medicare claims. Healthcare fraud is an organized crime that involves peers of providers, physicians, beneficiaries acting together to make fraud claims. Insurance companies are the most vulnerable institutions impacted due to these bad practices. Due to this reason, insurance companies increased their insurance premiums, and as a result, healthcare is becoming costly matter day by day.
Healthcare provider fraud is one of the biggest problems facing Medicare. According to the government, the total Medicare spending increased exponentially due to fraud in Medicare claims. Healthcare fraud is an organized crime that involves peers of providers, physicians, beneficiaries acting together to make fraud claims. Insurance companies are the most vulnerable institutions impacted due to these bad practices. Due to this reason, insurance companies increased their insurance premiums, and as a result, healthcare is becoming costly matter day by day.
Just an example to show how big this problem is, According to HHS and DOJ, Health Care Fraud and Abuse Control Program Annual Report for Fiscal Year 2013, February 2014 (http://oig.hhs.gov/publications/docs/hcfac/FY2013-hcfac.pdf), Four hospital executives in Florida were convicted of paying bribes and kickbacks to obtain Medicare patients. The executives billed Medicare for treatments for which the patients were ineligible, falsified patient charts, and administered unnecessary psychotropic medications to make the patients appear to need intensive mental health services. Relationship scrutiny played an important part in this case; it revealed that providers were taking advantage of their patients by over-treating them and billing the government.
Healthcare fraud and abuse take many forms. Some of the most common types of frauds by providers are:
· Billing for services that were not provided.
· Duplicate submission of a claim for the same service.
· Misrepresenting the service provided.
· Charging for a more complex or expensive service than was actually provided.
· Billing for a covered service when the service actually provided was not covered.
Anomaly Detection
Even though the fraudulent claims make a big impact on insurance companies, the fraud claims were only 2% of the whole claims. Since it is the low percentage of fraud. When analyzing normal claims these fraud claims often deviate from other normal claims as anomalies. These particular claims are different in that they do not match other expected patterns in the dataset. Such cases are commonly known as anomalies or rare events. This detecting these anomalies using machine learning algorithms helps to identify fraudulent providers.
There are many ML algorithms and packages available for this Anomaly detection; here the few...
· K-Nearest Neighbors
· Autoencoders - Deep neural network
· K-means
· Support Vector Machine
· Naive Bayes
Since the fraud claims instance was low in number and makes in a highly imbalanced dataset, the unsupervised algorithm machine learning algorithm better for this problem. I used the new neural network architecture called Autoencoder. Let us see how the autoencoder will work and I solved the fraud detection problem.
Autoencoder
Autoencoders algorithm is similar to dimensionality reduction techniques like principal component analysis which helps to identify important features in the data and features were noise and can be removed. This autoencoder is an unsupervised machine learning that takes input and reconstructs the input using the neural network. You maybe wonder what is the purpose of creating an output as same as the input. This autoencoder while reconstructing the input it learns the weights to reconstruct. These weights help us to identify how much deviate from the input dataset patterns.

The Autoencoder architecture has an input layer and the output layer has along with several hidden layers. In this architecture, the number of neurons keeps decrease until the middle. This process from the input layer is called the encoding process. The space represented by these fewer number of bits is called the “latent-space” and the point of maximum compression is called the bottleneck. After the model reaches this bottleneck layer, the model will try to reconstruct the input and increase the neurons until the output layer. This step is called the decoding process.
In the above picture (source: https://www.deeplearning-academy.com/p/ai-wiki-deep-autoencoder) -a 2-layer autoencoder with three hidden layers. The input and output layers have the same number of neurons. We feed six real values into the autoencoder which is compressed by the encoder into three real values at the bottleneck (middle layer). Using these three real values, the decoder tries to reconstruct the original six real values which we had fed as an input to the network.
Data
For this article, I used publicly available dataset in the Kaggle’s Healthcare Provider Fraud Detection Analysis (https://www.kaggle.com/rohitrox/healthcare-provider-fraud-detection-analysis) completion site. The dataset has Inpatient claims, Outpatient claims, and Beneficiary details of each provider. Also, the dataset has a provider list with a label whether fraudulent or not.
Here is the detail of the data.
· Inpatient Data - This data provides insights about the claims filed for those patients who are admitted to the hospitals. It also provides additional details like their admission and discharge dates, admitted date, and diagnosis code.
· Outpatient Data - This data provides details about the claims filed for those patients who visit hospitals and not admitted.
· Beneficiary Details Data - This data contains beneficiary KYC details like health conditions, Regio region they belong to, etc.
Feature Engineering
For this analysis, I limited feature engineering efforts to only numerical data and removed irrelative features such as admission related dates and race.
· Numeric to categorical mappings: Aggregated financial related features by provider id, beneficiary code, and physicians.
· Grouping sparse classes: For diagnosis code, procedure code which highly sparse with many codes that have low sample counts. I did group high-frequency codes as it is and other remaining ones into a single "Other" code.
· Creating dummy variables: I did manually transform categorical features into dummy variables for features diagnosis code, fatal code, and procedure codes.
H2O Implementation
Machine Learning Platform used in here is H2O, which is a Fast, Scalable, Open source application for machine/deep learning. The specialty of h2o is that it is using in-memory compression to handles billions of data rows in memory, even in a small cluster. It is easy to use APIs with R, Python, Scala, Java, JSON as well as a built-in web interface, Flow You can find more information here: https://www.h2o.ai
My input has 213 input features and I stared the model with 4 fully connected hidden layers were chosen with, [30,10,10,30] the number of nodes for each layer. First two for the encoder and last two for the decoder.
Here is the model parameters and script. Please take look at the full code in my GitHub
anomaly_model = H2ODeepLearningEstimator(activation = "Tanh",
hidden = [30,10,10,30],
epochs = 100,
standardize = True,
stopping_metric = 'MSE', # MSE for autoencoders
loss = 'automatic',
train_samples_per_iteration = 32,
shuffle_training_data = True,
autoencoder = True,
l1 = 10e-5)
anomaly_model.train(x=x, training_frame = train_h2o)
Model Loss
The model seems to be converged from the second epoch itself. I used the simple a well enough, although there is significant room for improvement. This simple autoencoder architecture was chosen for ease of explanation within this approach for the complex healthcare data. The overall performance could be improved by adding more hidden layers. More hidden layers would allow this network to encode more complex relationships between the input features.
Reconstruction Error Check
Autoencoders are trained to reduce reconstruction error which we show below:
predictions = anomaly_model.predict(test_h2o)
error_df = pd.DataFrame({'reconstruction_error': test_rec_error_df['Reconstruction.MSE'],'true_class': Y_test_df})
error_df.describe()
reconstruction_error
|
true_class
| |
count
|
1077.000000
|
1077.000000
|
mean
|
0.015079
|
0.083565
|
std
|
0.310764
|
0.276864
|
min
|
0.000011
|
0.000000
|
25%
|
0.000022
|
0.000000
|
50%
|
0.000083
|
0.000000
|
75%
|
0.000328
|
0.000000
|
max
|
9.872896
|
1.000000
|
ROC Curve Check

Since we have an imbalanced data set they are somewhat less useful, the near-perfect ROC curve is expected. Because proportionally few claims (2%) of fraud, we can generate a pretty good-looking curve by just simply put every claim is normal makes 98% accuracy.
Recall vs. Precision Thresholding

Precision and recall are the eternal tradeoffs in data science, so at some point, you have to draw an arbitrary line or a threshold. Where this line will be drawn is essentially a business decision. Now let's look at recall vs. precision to see the trade-off between the two.
In this case, you are trading off the cost between missing a fraudulent transaction and the cost of falsely flagging the transaction as a fraudulent even when it is not. Add those two weights to the calculation and you can come up with some theoretical optimal solution. In a real business, scenario deciding the threshold is not an easy task must be taken several factors (of course customer emotions when rejecting a legitimate claim as a fraud. For this article, and based on the current result, I choose the threshold as 0.01.
Now that we have talked with the business client and established a threshold, let's see how that compares to reconstruction error. Where the threshold is set seems to miss the main cluster of the normal transactions, but still get a lot of the fraud transactions.
Classification Report
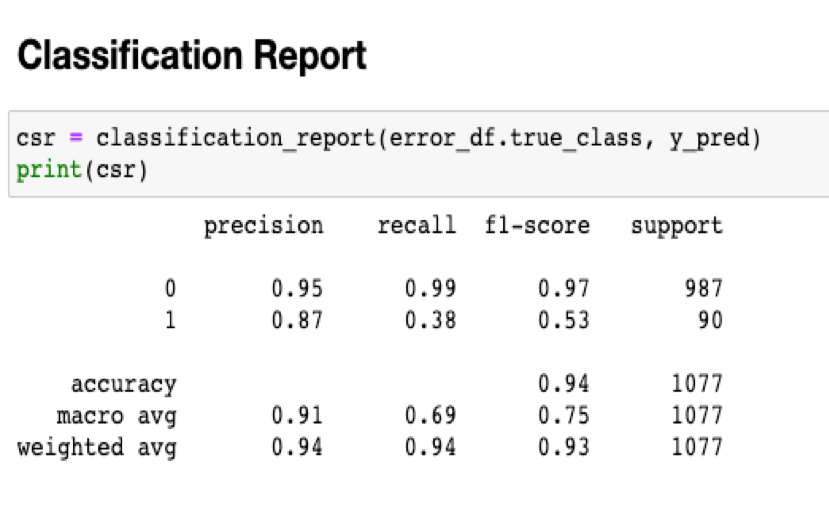
Finally, we take a look at a traditional Classification Report for the testing set. You will also notice we caught only 53% of the fraud claims, which might seem low at face value. Remember, I have not used all the features in the data. Also, for this model I assumed that every claim from the fraudulent provider is a fraud.
Conclusion
In this article, I presented the healthcare frequent provider case and explain how you can use the anomaly detection technique to find the detect the fraudulent medical claim. As I mentioned, I assumed that every claim from fraudulent provide is a fraud, and I used limited features. In addition, I didn’t try many options in the model architecture. Many ways overall performance could be improved by adding more hidden layers. More hidden layers would allow this network to encode more complex relationships between the input features. Finally, I explained and ran a simple autoencoder in the H2O deep learning platform. Hope this useful for few if not many,
Full code for this solution is available in my GitHub
Thanks,
Appreciate your “Like” click.
References:

Comments
Post a Comment